윈도우즈 시스템 프로그래밍 4장-세션1
시작 전 소개

1챕터 정리본 바로가기
2챕터 정리본 바로가기
3챕터 정리본 바로가기
4장의 경우 1세션만 해도 md파일이 100줄이 넘어가서 세션당으로 정리하거나 두 세션을 하나의 게시물로 엮는 방식으로 게시할 예정입니다.
컴퓨터 구조의 접근방법
1세션에서는 주로 레지스터에 대한 내용을 다룬다.
그렇다면 왜 cpu의 장치중에 ALU나 컨트롤 유닛이 아닌 레지스터를 다룰까?
찾아보니 CPU디자인을 할 때에는 명령어 디자인과 레지스터 디자인이 초기단계에서 이루어지고
레지스터셋이 결정되어야 하드웨어 전체를 구상할 수 있다고 한다.
또한 레지스터를 결정하여야 해당 명령어 집합 아키텍처(ISA)가 결정할 수 있는데
이 ISA는 최하위 레벨의 프로그래밍 인터페이스여서 프로세서가 실행할 수 있는 모든 명령어를 담고있다.
그렇기 때문에 프로그래밍을 하기 위해서는 레지스터를 제일 먼저 디자인하는 것이다.
레지스터 디자인과 명령어 디자인
[레지스터 디자인 시 핵심요소]
- 레지스터를 몇 비트로 구성할 것인가
- 몇 개의 레지스터로 구성할 것인가
- 그 각각의 레지스터를 어떤 용도로 사용할 것인가?
(레지스터는 시스템 비트수와 일치하도록 설계한다)->명령어 길이가 n비트이니 레지스터의 비트도 n비트여야한다.
책에서는 공부 내용의 난이도 조절을 위해 8개의 레지스터를 16비트로 구성할 것이다.
저자는 다음 그림과 같이 레지스터를 구성하였다.
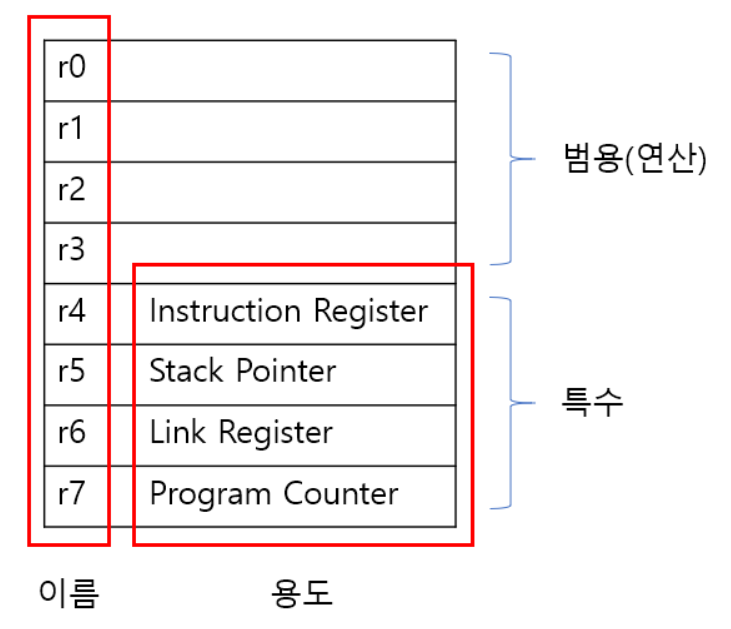
유의점은 위에서 말했다시피 레지스터의 구성형태에 따라서 명령어의 구조 역시 변경되어야한다.
그런데, 어셈블리 언어로 구현된 프로그램은 구조가 다른 CPU로 이식이 불가능하다.
저자는 레지스터 크기와 명령어의 길이를 똑같게 맞추어 디자인을 하였다.
어떻게 일 해야 할까
2의 16승 만큼 어떠한 명령어들을 만들게 되면 지나치게 많은 명령어가 생기게된다.
또한 연산이 이루어질 때 단순히 +에 대한 명령어만 만들면 되는 것이 아니라
우리가 변수를 설정해서 계산하듯 레지스터 1의 값,더하기,저장할 위치,더할 숫자라는 정보를 보낼 수 있어야한다.
본격적인 명령어 디자인
사칙연산을 하기 위해서는 최소한 2개의 비트가 있어야한다.
그래서 저자는 3비트 연산자에 할당하여
001/010/011/100으로 사칙연산을 나타내었다.
사실 이 부분에서 나는 사칙연산에는 4개의 종류가 있으니 2비트만 할당해도 되지 않나 했는데
저자는 3칸을 할당하였다.
아마 C/c++에도 100개의 키워드가 있다는 이야기를 했기 때문에
단순 사칙연산 이외에도 우리가 프로그래밍을 하며 사용하는 연산자들도 필요시 만들기 위해 자리를 미리 할당한 것으로 보인다.
저장소는 3개의 비트를 사용하였는데, 이는 레지스터가 8개이기 때문이다.
이곳에는 항상 연산결과를 저장할 저장소 레지스터 정보만 올 수 있도록 해야한다.

보면 사칙 연산에 대해 작성한 2진 코드와 저장소에 대해 작성한 2진코드가 위치한다.
저자의 구조에 대한 의문
그런데 나는 여기에서 이상한 점을 느꼈는데, 인간이 생각하는 방식 대로라면 계산을 하고 저장소에 넣는 것이 맞지 않는가라는 거였다.
우선 ARM기반의 아키텍처를 토대로 저자가 직접 짠 구조라고 해서 ARM아키텍처에 대해 조사해보니
32비트 64비트의 아키텍처의 경우 꼭 미리 저장소를 할당할 필요는 없다는 것을 알게되었다.
즉 16비트라는 제한된 공간을 효율성 있게 사용하기 위해 미리 저장소를 레지스터에 할당한다거나
임시적으로 사용할 레지스터의 역할을 정해주는 등의 최적화 작업을 한 것으로 보인다.
본론으로 돌아와서
그렇게 위에 작업을 통해 r2라는 저장소를 미리 할당한 것에 대한 의문은 끝났다.
피연산자 r1에 굳이 4개의 비트를 할당한 것은 명확성과 관계있다.
사실 r1은 처음 계획대로면 2진코드 상으로 001이라는 코드를 가지게 되지만, 이렇게 작성하면 숫자 1이 피연산자인지 레지스터가 피연산자인지 구분하기 어려워진다.
원래대로면 r1의 내용물과 연산을 진행해야하는데 숫자 1과의 덧셈을 진행하면 잘못된 결과가 나올 수 밖에 없다.
따라서 한 칸을 더 할당하여 레지스터일 때는 맨 앞에 칸을 1로 숫자일 때에는 0으로 약속하였다.
7을 0111로 나타낸 부분은 앞과 똑같은 원리이기 때문에 7의 2진수로 나타낸 결과값인 111과 숫자임을 나타내는 0으로 조합된 것으로 보인다.
종합적인 정리
🟢현재까지 해온 과정은 어셈블리 언어 기반의 프로그램 구현
(연산자인 ADD,r2,r1,7)이다.
이를 cpu가 인식할 수 있는 하나의 2진 명령어 형태로 변환하는데,
이 과정이 바로 아까 말한 ADD=001과 같은 과정이다.
[연산의 과정]
◼단계 1: 어셈블
내가 하고자하는 작업에 따라 0과 1로 이루어진 연산들을 할당한다.
◼단계 2: 메모리 로드
1단계에서 작성한 프로그램의 메모리에 실제로 올리는 단계
◼단계 3: 패치
입출력 버스에 단계2를 통해 올라온 코드를 ir메모리로 옮긴다.
◼단계 4: DECODE
해석의 단계
ir메모리에 올라온 코드가 어떤 동작을 해야하는 코드인지 해석한다.
◼단계 5: Exeution
컨트롤 유닛에 올라온 해석된 코드를 ALU로 보내어 연산을 진행한다.
RISC VS CISC
🟩CISC(Complex Instruction Set Computer)
복잡한 명령어 체계를 가지는 컴퓨라는 의미로 수백 개의 명령어 구성이 가능하기도 하다.
다양한 명령어의 종류가 주는 이점도 있으나,
그 크기가 일정하지 않다는 특징 때문에 복잡한 구조로 인하여 성능향상의 제한이 따르게 된다.
🟩RISC
위에서 말한 문제들을 해결하기 위해 착안된 구조이다.
CISC의 복잡한 명령어셋이 주는 이점도 있으나, 주로 사용하는 명령어는 10%밖에 되지 않는다는 데에서 시작되었다.
명령어의 수를 대폭 줄이는 대신 명령어의 구조를 일정하게 디자인하였으며 파이프라이닝 기법에 의해 클럭 당 둘 이상의 명령어 처리 역시 가능해졌다.
댓글남기기